
During the propagation delay, different regions might see different values. This is “Temporary Inconsistency” or “Temporary Discrepancy”.
Question: Is this ‘Temporary Inconsistency’ unavoidable? If not, is it possible to minimize it?
Answer:
These temporary discrepancies are generally unavoidable in systems designed for eventual consistency. This is because the primary goal of such systems is to ensure high availability and partition tolerance, often at the expense of immediate consistency – a fundamental constraints described in the CAP theorem.
In distributed systems, especially those spread across multiple geographic locations, achieving immediate consistency can be challenging due to network latency and the time it takes for updates to propagate to all nodes. Eventual consistency allows the system to remain available and responsive even when some nodes are temporarily out of sync.
However, there are strategies to minimize the impact of these discrepancies. For example:
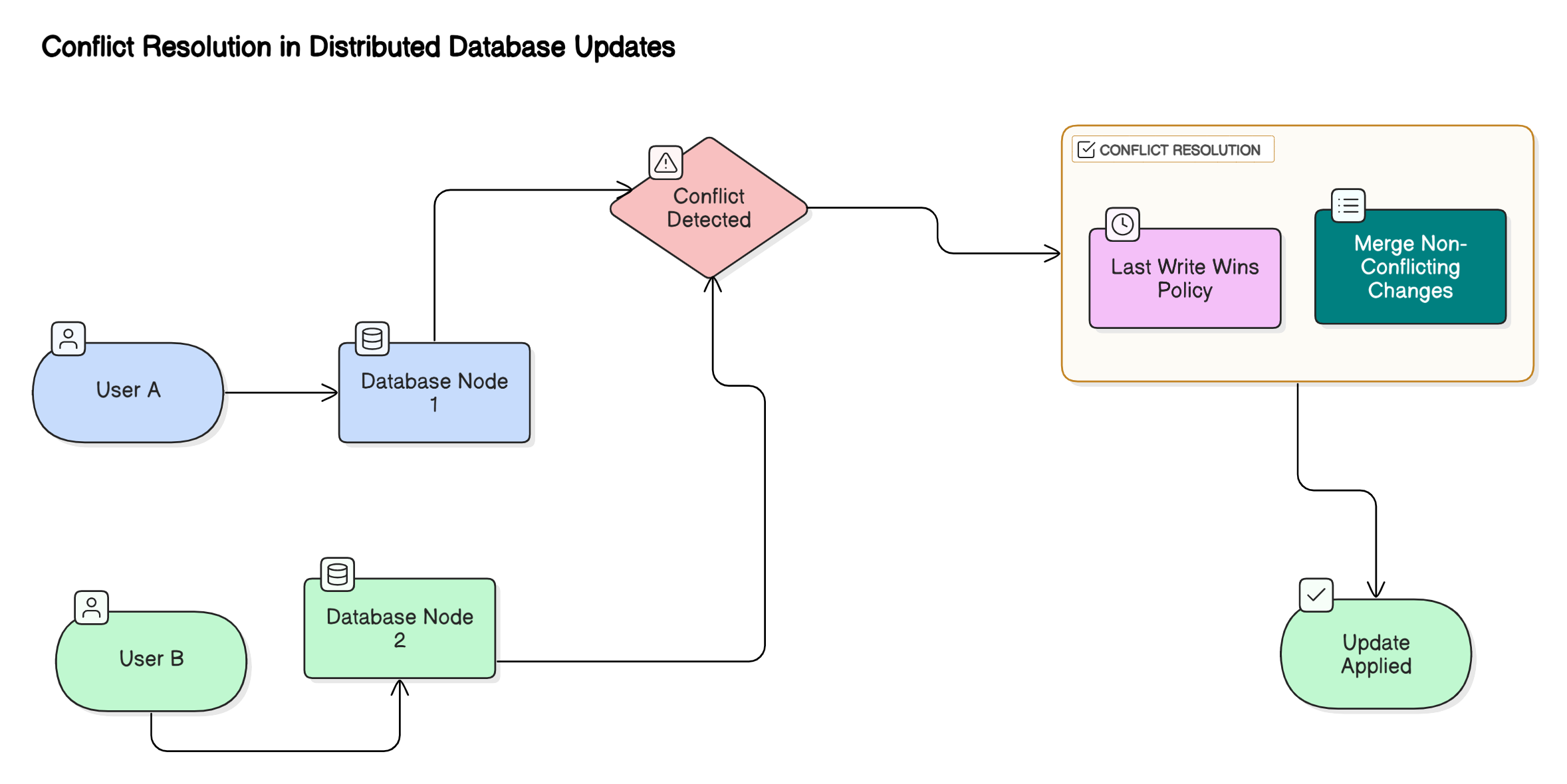
Conflict resolution strategy
- Description: A conflict resolution strategy is used in distributed systems to handle situations where multiple replicas receive conflicting updates to the same data item, often due to concurrent writes or network partitions. Common approaches include “last write wins,” merging values, or using application-specific logic to reconcile differences when replicas synchronize.
- Benefit: This ensures data integrity and consistency across replicas, allowing the system to automatically resolve discrepancies and maintain a coherent state without manual intervention.
- Example: In a distributed database, two users might update the same record simultaneously on different nodes. To resolve this conflict, the system could use a “last write wins” policy (LWW), where the most recent update (based on a timestamp) is accepted. Alternatively, it could merge the changes if they are not conflicting (e.g., combining lists of items).
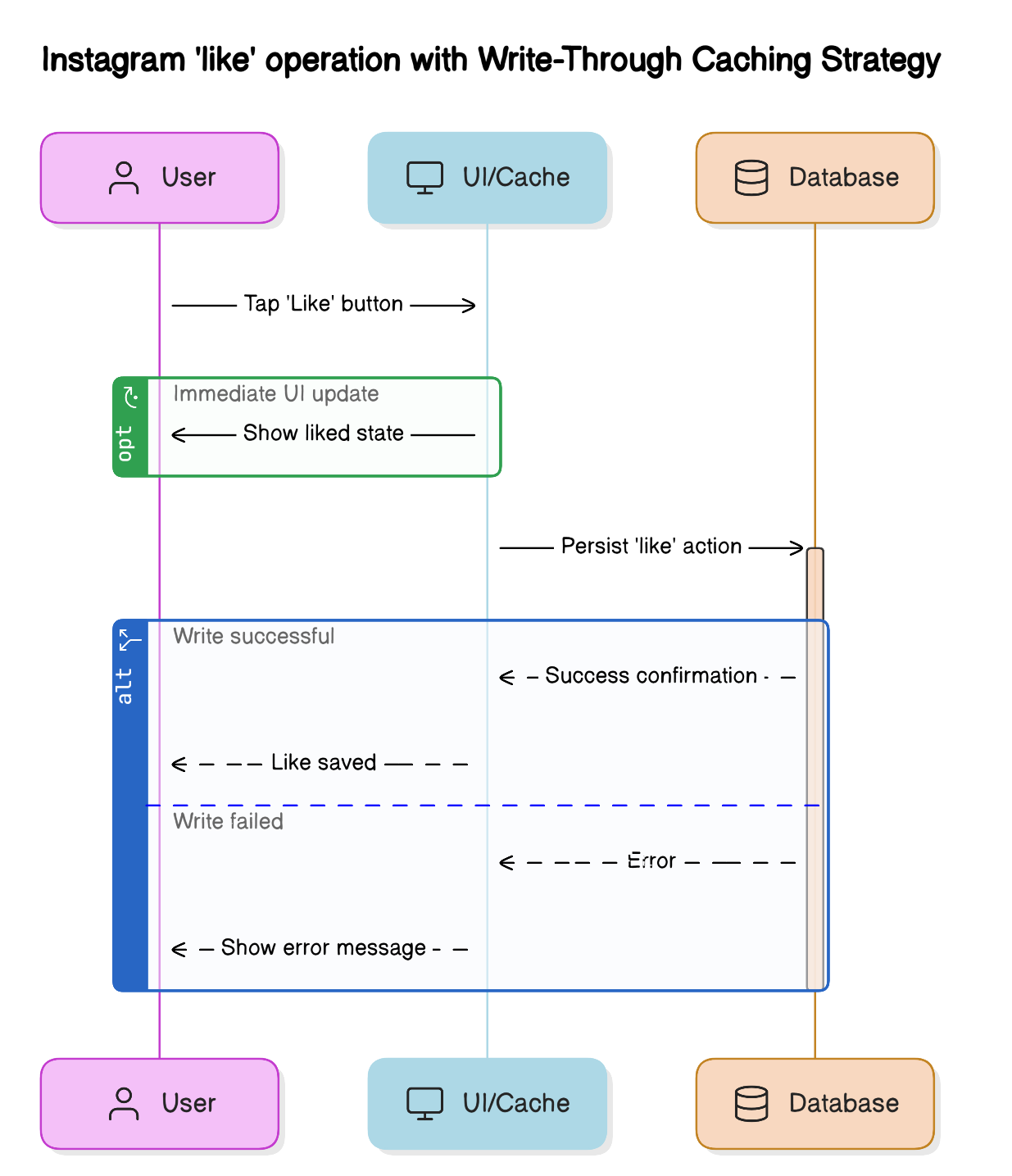
Write-Through Caching strategy
- Description: Write-through caching is a technique where every write operation is immediately applied to both the cache and the underlying database. This ensures that the cache always contains the most up-to-date data, and any read from the cache reflects the latest committed state.
- Benefit: It provides strong consistency for read operations, reduces the risk of stale data, and improves application responsiveness by serving fresh data directly from the cache.
- Example: Let’s think of the “likes” in an Instagram post. When you like a post on Instagram, the application immediately updates the UI to show your like. At the same time, it updates a backend cache and the permanent database. This ensures you see the change instantly, and the new like count is quickly and reliably reflected for all users.
Read Repair strategy
- Description: Read repair is a mechanism where, during a read operation, the system detects inconsistencies between replicas and automatically updates out-of-date replicas with the correct data. This repair process happens in the background as part of normal read requests.
- Benefit: It gradually restores consistency across replicas without requiring dedicated repair jobs, ensuring that frequently accessed data remains accurate and up-to-date.
- Example: Suppose a user reads data from a distributed database, and the system detects that some replicas are out of sync. During the read operation, the system can fetch the latest data from the most up-to-date replica and simultaneously update the out-of-sync replicas. This ensures that future reads will be consistent.
Retry Mechanism
- Description: A retry mechanism automatically re-attempts failed operations, such as writes or reads, in the event of transient errors like network timeouts or temporary unavailability of a replica. Retries are often performed with exponential backoff to avoid overwhelming the system.
- Benefit: This increases the reliability and robustness of the system, ensuring that temporary failures do not result in lost or incomplete operations and improving the overall user experience.
- Example: Consider a payment processing application. If a payment gateway is temporarily down, system automatically retries after 5 seconds, then 10 seconds, then 20 seconds. After 3-4 attempts, it might notify the user to try again later.
Optimized Network Topology
- Description: Optimized network topology involves designing the physical and logical arrangement of servers and data centers to minimize latency, maximize throughput, and ensure efficient data replication across regions. This can include strategies like placing replicas closer to users or using dedicated high-speed links between data centers.
- Benefit: It enhances the performance and availability of the system, reduces the time required for data propagation, and helps maintain a better balance between consistency, latency, and fault tolerance.
- Example: Netflix uses a three-tier network to deliver high-quality video globally:
- Content is first stored in a central repository (Tier 1),
- then distributed to regional hubs (Tier 2),
- and finally to local ISP servers called Open Connect Appliances (OCAs, Tier 3) near end users.
- For example, when a user in Tokyo streams “Stranger Things,” the video is served from a nearby OCA, ensuring fast, smooth playback.When new content is released, it’s uploaded to the central repository and then gradually propagated to regional hubs and local OCAs. This means there may be a short period where the latest episode is available in some locations but not yet on all local servers—a temporary inconsistency. As updates finish propagating, all users gain access to the new content, achieving eventual consistency. This optimized network topology improves streaming speed, reduces costs, and enhances user experience, while ensuring all users eventually see the latest content.

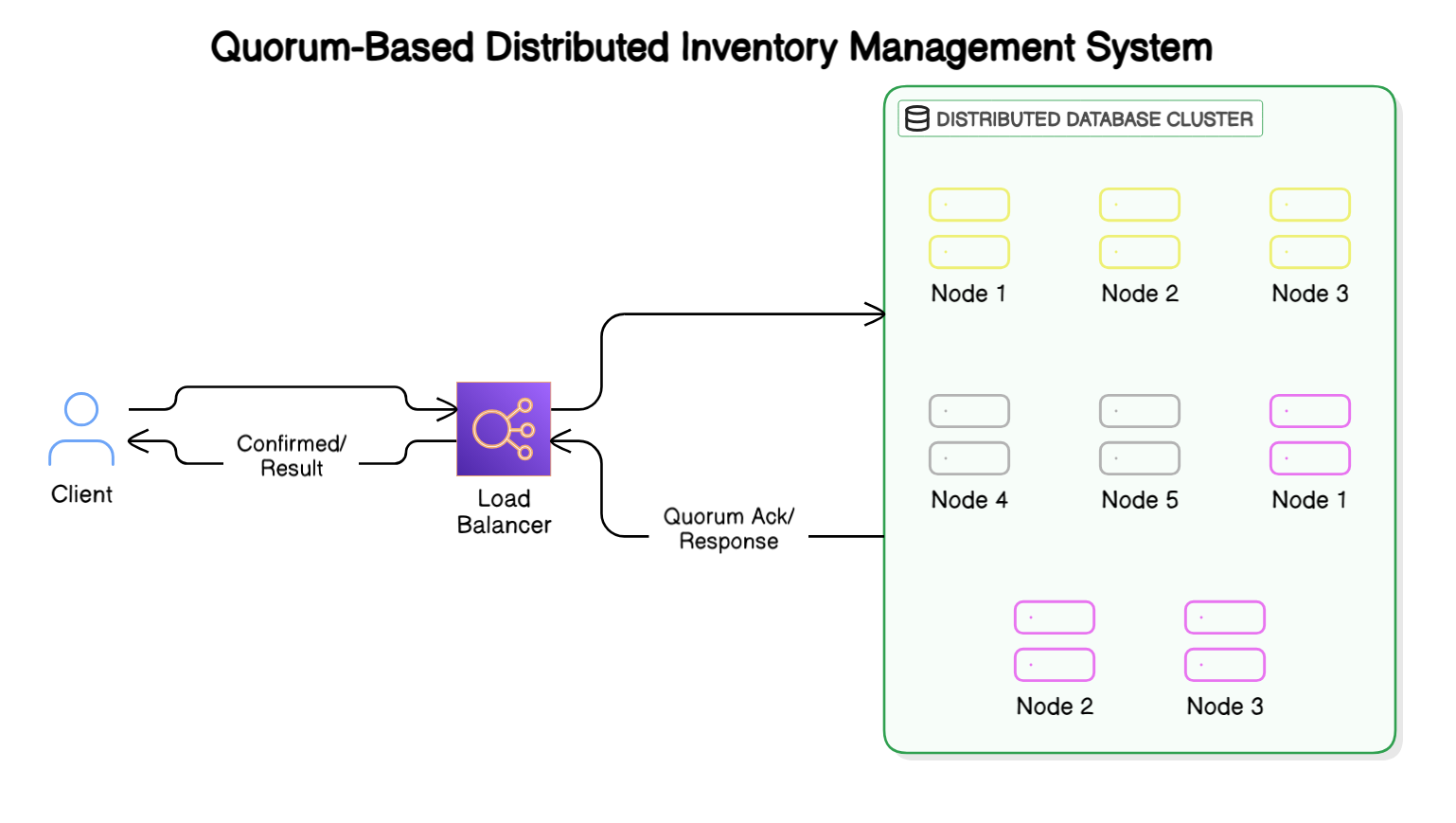
Quorum-based strategy
- In a quorum-based system, when a user writes data, the system requires a majority (quorum) of nodes to acknowledge the write before considering it successful. A quorum is the minimum number of nodes that must participate in a successful read or write operation.
- Two main numbers are involved:
R = Read quorum (number of nodes that must participate in a successful read)
W = Write quorum (number of nodes that must participate in a successful write)
N = Total number of nodes in the system - Quorum Rules
To ensure consistency, the following must be true:
R + W > N (Read and Write quorum must overlap)
W > N/2 (Write quorum must be majority to prevent conflicts) - Example: Imagine a globally distributed social media platform’s notification system where users can receive and interact with notifications across different geographic regions. When a user creates a post that triggers notifications to their followers, the system uses a quorum-based approach with 5 data centers (N=5) spread across different continents. With a write quorum (W=3) and read quorum (R=3), when a celebrity posts content that triggers millions of notifications, the system writes the notification data to at least 3 data centers before confirming success to the user. When followers from different regions check their notifications, their local apps query at least 3 data centers to ensure they get the most recent notifications, even if some data centers are temporarily down or experiencing high latency. This setup ensures that the notification system remains highly available (followers can still see notifications even if 2 data centers fail) while maintaining eventual consistency (all followers will eventually see the same notification state, even if there’s a brief delay in propagation to all data centers), making it an ideal balance for a social media platform where immediate consistency is less critical than system availability and user experience.
There are a few other consistency models or strategies such as, Mixed consistency or Multi-level consistency model (also known as Adaptive or Tuneable consistency), Vector Clocks strategy, Conflict Resolution Strategy, Anti-Entropy Mechanism, Versioning and Timestamps, Monitoring and Alerts etc.
These strategies can help reduce the duration and impact of temporary discrepancies, but they cannot eliminate them entirely without sacrificing the benefits of high availability and partition tolerance.
